
1 我的爬虫是在本地win10电脑上面写的,用的是srcapy框架。scrapyd部署在一个内网的centos8的机器上,利用本地的scrapyd-client将爬虫同步到centos8的机器上,然后本地执行命令启动服务器的爬虫。
2 本地win10环境搭建
安装python3.7+(https://www.python.org/downloads/)
安装Pycharm 编辑器 (这个编辑器,安装插件,编写代码非常方便)
在Pycharm中新建一个项目(File -> NewProject)
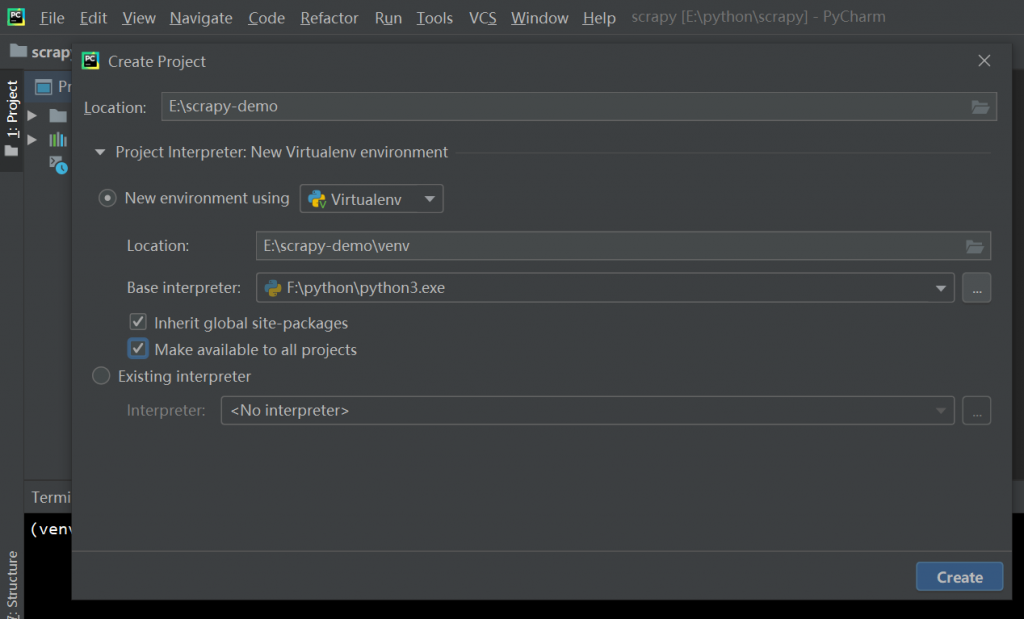
安装scrapy包 (File -> setting), 点击红框中的加号,如果安装失败,可能要翻下墙,或者使用国内的镜像源(https://www.laoqiange.club/2020/03/17/tips/)
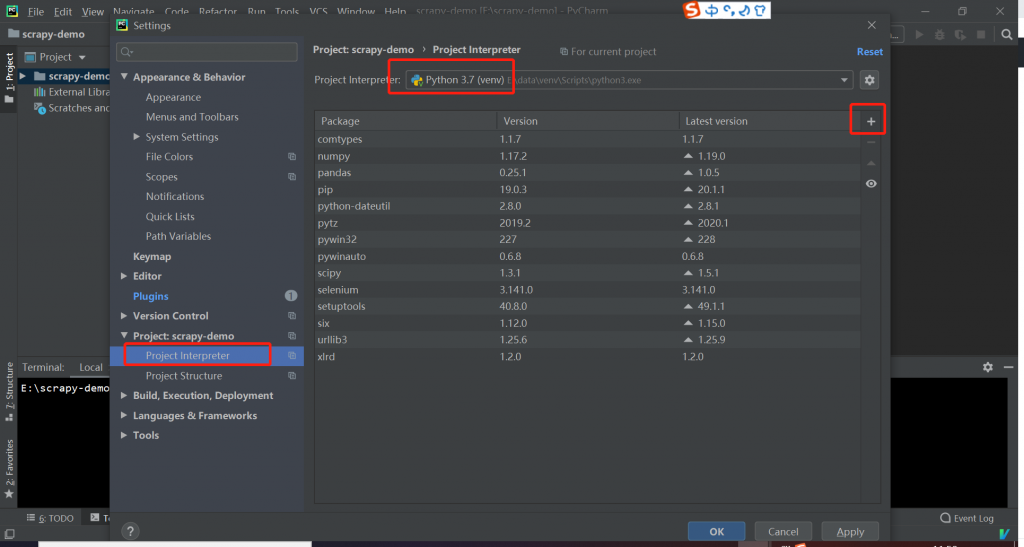
安装 scrapyd-client (同上),在window下 scrapyd-client不能直接使用需要修改下配置在scrapyd-deploy 的同级目录下建一个scrapy-deploy.bat的文件。文件内容如下。
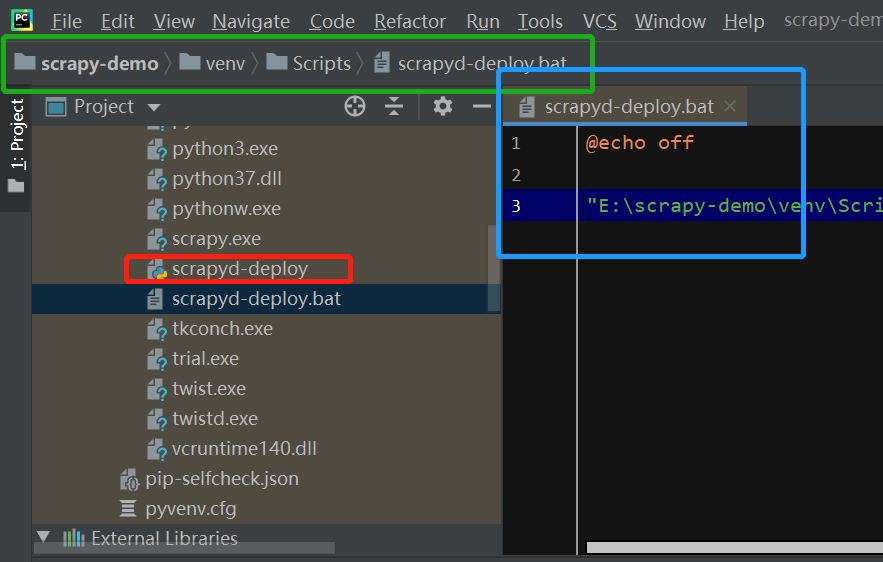
@echo off "E:\scrapy-demo\venv\Scripts\python3.exe" "E:\scrapy-demo\venv\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
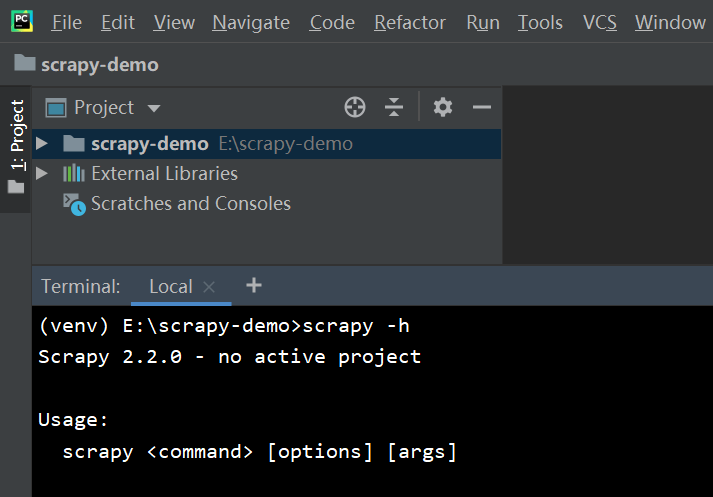
测试是否安转成功
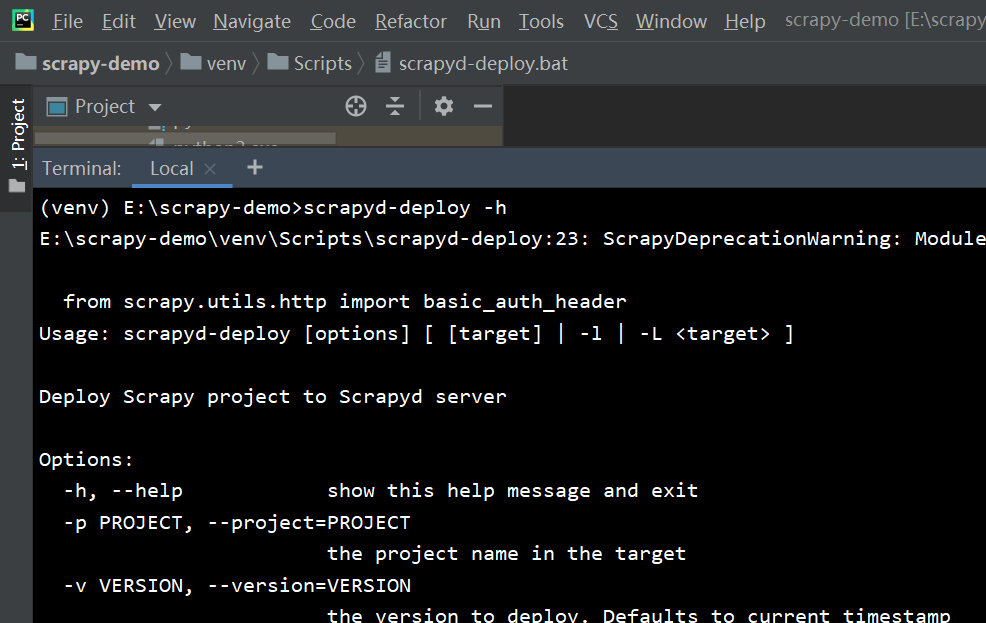
3. 搭建centos8 的环境
安装python3.7+ (https://www.laoqiange.club/2019/11/29/centos7-chrome-selenium/)
安装scrapyd
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapyd
新建文件 /etc/scrapyd/scrapyd.conf
[scrapyd] eggs_dir = eggs logs_dir = logs items_dir = jobs_to_keep = 5 dbs_dir = dbs max_proc = 0 max_proc_per_cpu = 4 finished_to_keep = 100 poll_interval = 5.0 bind_address = 0.0.0.0 http_port = 6800 debug = off runner = scrapyd.runner application = scrapyd.app.application launcher = scrapyd.launcher.Launcher webroot = scrapyd.website.Root [services] schedule.json = scrapyd.webservice.Schedule cancel.json = scrapyd.webservice.Cancel addversion.json = scrapyd.webservice.AddVersion listprojects.json = scrapyd.webservice.ListProjects listversions.json = scrapyd.webservice.ListVersions listspiders.json = scrapyd.webservice.ListSpiders delproject.json = scrapyd.webservice.DeleteProject delversion.json = scrapyd.webservice.DeleteVersion listjobs.json = scrapyd.webservice.ListJobs daemonstatus.json = scrapyd.webservice.DaemonStatus
4 本地创建爬虫
scrapy startproject demo // 创建项目 cd demo // 切换目录 scrapy genspider quotes quotes.toscrape.com // 建立爬虫
demo/demo/spider/quotes.py
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall()
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
运行爬虫
scrapy crawl quotes
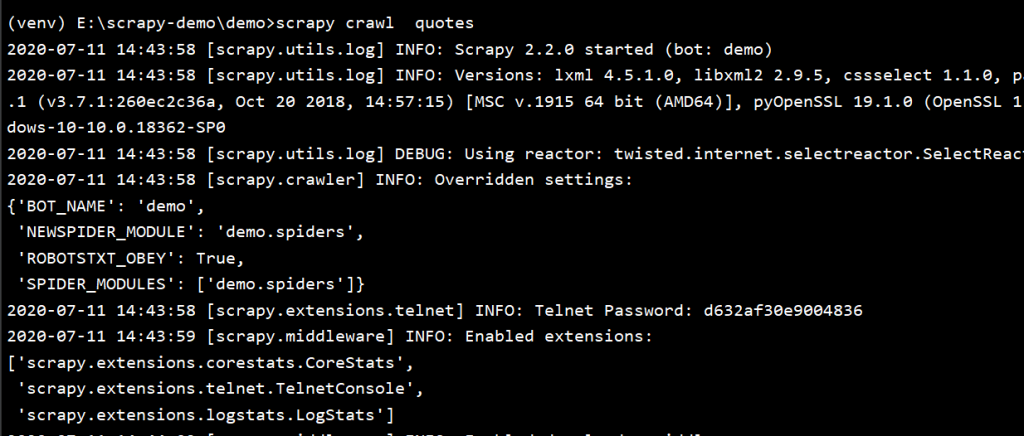
爬虫本地运行成功
5 服务器端运行
centos8服务器端运行scrapyd
scrapyd
win10服务器上传脚本
修改demo/scrapy.cfg 文件
# Automatically created by: scrapy startproject # # For more information about the [deploy] section see: # https://scrapyd.readthedocs.io/en/latest/deploy.html [settings] default = demo.settings [deploy] url = http://192.168.0.102:6800/ project = demo
同步代码到服务器
scrapyd-deploy
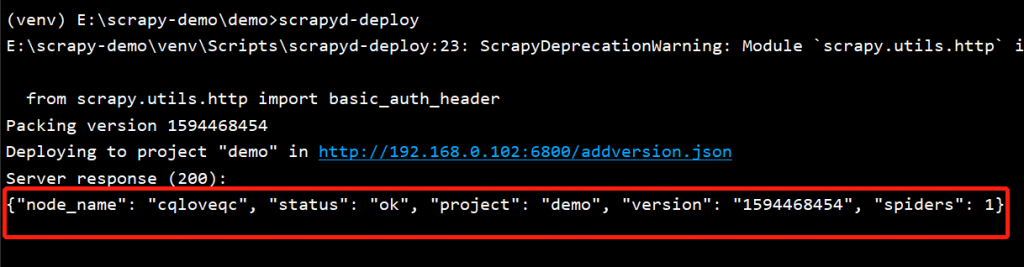
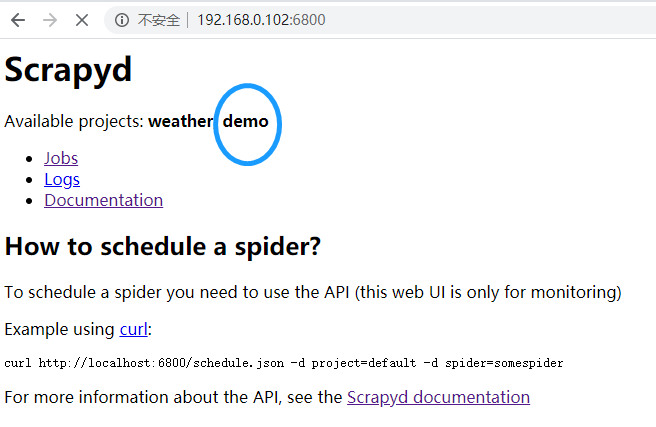
有上述显示就表示上传成功
服务器端执行爬虫
curl http://192.168.0.102:6800/schedule.json -d project=demo -d spider=quotes


如上图显示抓取成功,不过抓取的内容到输出到日志中了,可以把抓取的内容输出到MongoDB中,我这边不贴代码了,贴一下最后的结果。
