1.安装scrapydweb
pip3 install scrapydweb // 安装scrapydweb scrapyweb // 启动scrapydweb
2. 配置scrapydweb
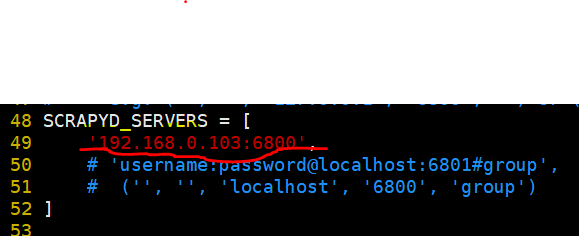
启动scrapydweb后会在当前目录下生成一个配置文件 scrapydweb_settings_v10.py(如图增加上scrapyd的服务地址就行)
3. 安装logparser
scrapydweb用logpraser来管理scrapyd的日志,如果不安装就会报错(Request to http://192.168.0.103:6800/logs/demo/biquge/2020-09-26T22_54_59.json got code 404, wait until LogParser parses the log.)
pip3 install logparser // 安装logparser logparser // 启动logparser
4. 配置logparser(配置文件在/usr/local/lib/python3.6/site-packages/logparser/settings.py,在logparser包安装的目录之下)
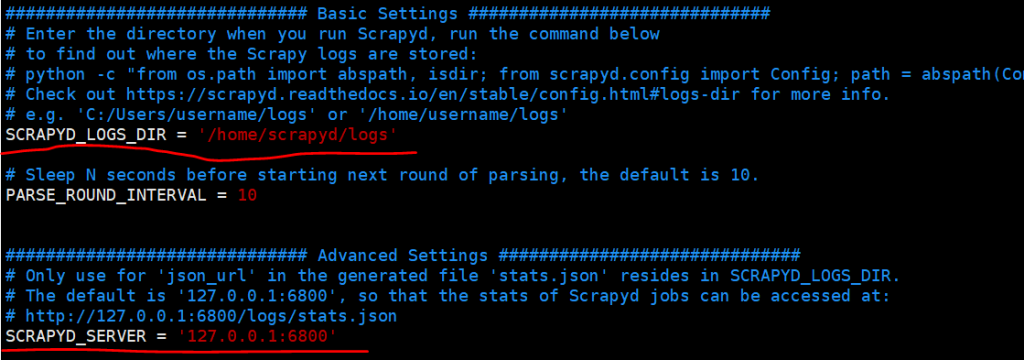
修改如图的两项
5. 注意事项
scrapydweb 可以安装在任意一台服务器上,但是需要把要管理的scrapyd服务的访问地址配置在配置文件中。
logparser 需要和scrapyd 安装在同一台服务器中,把scrapyd的目录地址配置在配置文件中。
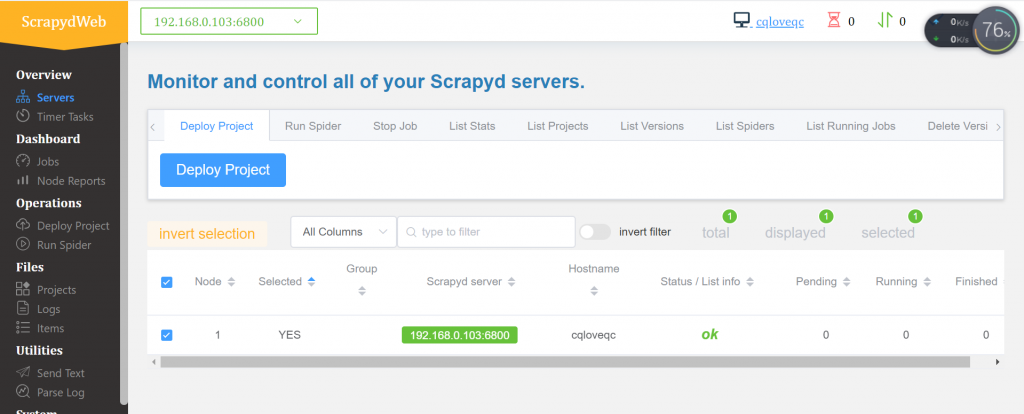
下图是安装成功之后的界面